- 欢迎使用千万蜘蛛池,网站外链优化,蜘蛛池引蜘蛛快速提高网站收录,收藏快捷键 CTRL + D
Python3入门机器学习:从零到一掌握基础知识,打造机器学习端到端场景
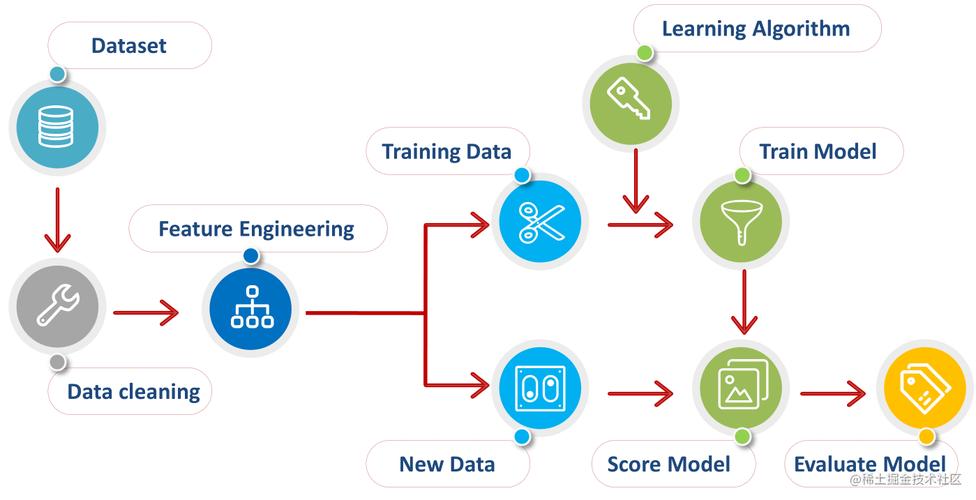
在进行机器学习项目之前,我们需要先进行一些环境准备工作。首先,我们需要安装Python3,作为机器学习项目常用的编程语言。另外,还需要安装一些机器学习库,如scikitlearn、numpy、pandas等,以便处理数据和构建模型。最后,我们还需要安装Jupyter Notebook或其他集成开发环境(IDE)来进行代码编写和实验。
为什么要进行数据预处理?
在进行数据分析和建模前,我们需要对数据进行预处理。这包括数据的收集、清洗、转换和划分。数据收集可以通过网络爬虫、API接口、数据库等方式获取。数据清洗则是去除数据中的空值、重复值和异常值,以确保数据质量。数据转换包括归一化、标准化和独热编码等方法,以便模型更好地学习数据特征。最后,数据划分将数据集分为训练集和测试集,用于模型训练和评估。
如何选择合适的模型?
在建模过程中,选择合适的模型至关重要。常用的机器学习模型包括线性回归、逻辑回归、决策树、随机森林、支持向量机、K近邻算法和神经网络等。不同的问题适合不同的模型,选择合适的模型有助于提升模型性能和预测准确度。
如何训练和评估模型?
在选择模型后,我们需要导入模型库,创建模型对象,拟合模型并调整超参数以找到最佳模型。在训练完成后,我们需要对模型进行评估,包括预测测试集、计算评估指标如准确率、精确率、召回率、F1分数和可视化结果如混淆矩阵、ROC曲线等。
如何部署模型?
最后,训练好的模型需要保存并部署到生产环境中。这包括将模型保存到文件中、加载模型到应用程序中以及应用模型进行实时预测。部署模型是机器学习项目的最终目标,让模型能够为实际业务提供决策支持。
推荐问题
在进行机器学习项目时,你遇到过哪些挑战?如何解决这些挑战?欢迎留言分享你的经验和想法。感谢观看!

相关文章推荐
- "Python3集成开发环境:轻量级OS Studio如何验证集成开
- PRC机器学习:如何应用机器学习实现端到端场景
- 1. 如何在Python3中连接MySQL数据库?简单配置教程 2.
- AI vs. 机器学习:探索AI技术和机器学习的区别,以及机器
- Python与机器学习基础:探索机器学习的入门之路 机器学
- 如何利用AOI机器学习技术构建端到端场景 AOI机器学习
- "如何使用Pandas进行机器学习?实战指南和端到端场景解
- 如何规划AI机器学习路线:解析机器学习端到端场景
- "为什么选择Python3 ?教你手把手安装,让你轻松开启科学
- Python3装饰器:如何优雅地扩展函数功能? | 装饰器详解
蜘蛛技巧最新文章
- 如何使用Linux下的find命令提高文件搜索效率? 1. “Linux下find命令详解:轻松搜索文件与文件夹” 2. “Linux下find命令全攻略:快速定位目标文件和目录” 3. “Linu
- APM翻译是什么?如何处理翻译难题
- 如何定制个性化的App?实现定制化需求的关键接口技巧
- "App和网站之间如何传数据?实际操作技巧分享" "APP备案和网站备案的区别?详细解读备案流程和要点"
- 安卓ssh服务器客户端: 如何配置并连接进行远程操作?IdeaHub Board设备安卓设置教程,轻松实现设备连接和管理
- PersistentVolumeClaims状态有什么问题?如何替换PersistentVolumeClaims
- 在微信中查看别人的朋友圈不会直接在对方的朋友圈记录中留下痕迹。但是,如果你给对方的朋友圈点赞、评论或者转发,对方在朋友圈中会收到通知,并且在对方的朋友圈消息提醒中会有相应记录。
- “避免SQL注入!mysql中tonumber函数使用要注意什么”
- "PostgreSQL企业版:提升数据库性能的最佳实践" "为什么你的企业需要考虑升级到PostgreSQL企业版?"
- PLSQL连接MySQL数据库:如何高效配置云数据库MySQL MySQL数据库连接:4个步骤轻松实现



)


)





