- 欢迎使用千万蜘蛛池,网站外链优化,蜘蛛池引蜘蛛快速提高网站收录,收藏快捷键 CTRL + D
1. 为什么多任务学习如此重要?设置MultiStatements处理模式的完整指南 2. 如何正确设置MultiStatements处理模式?多任务学习实践技巧分享
多任务学习(Multitask Learning)是一种机器学习范式,它允许同时学习多个任务,在多任务学习中,共享表示被用于执行多个相关任务,从而可以提高泛化能力并加速学习过程。
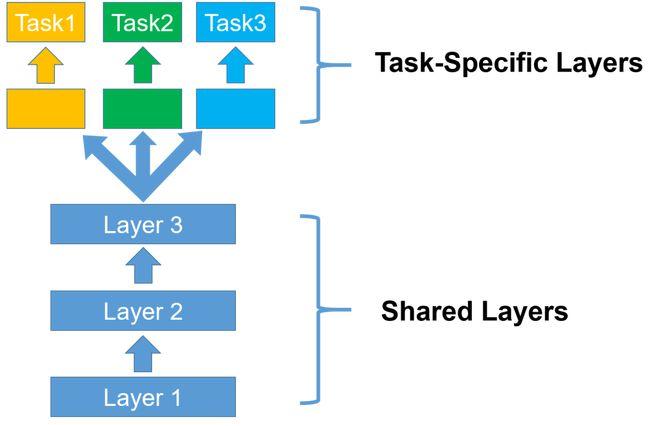
要设置 MultiStatements 处理模式,您可以使用以下步骤:
1、导入必要的库和模块:
import torchimport torch.nn as nn
2、创建多任务学习模型类:
class MultiTaskLearningModel(nn.Module): def __init__(self): super(MultiTaskLearningModel, self).__init__() # 定义共享层 self.shared_layers = nn.Sequential( nn.Linear(input_size, hidden_size), nn.ReLU(), # 添加更多共享层 ) # 定义任务1的特定层 self.task1_layers = nn.Sequential( nn.Linear(hidden_size, output_size_task1), nn.ReLU(), # 添加更多任务1的特定层 ) # 定义任务2的特定层 self.task2_layers = nn.Sequential( nn.Linear(hidden_size, output_size_task2), nn.ReLU(), # 添加更多任务2的特定层 ) def forward(self, x): # 前向传播通过共享层 x = self.shared_layers(x) # 前向传播通过任务1的特定层 task1_output = self.task1_layers(x) # 前向传播通过任务2的特定层 task2_output = self.task2_layers(x) return task1_output, task2_output
3、实例化模型并设置 MultiStatements 处理模式:
input_size = 100 # 输入特征维度hidden_size = 50 # 隐藏层维度output_size_task1 = 10 # 任务1的输出维度output_size_task2 = 5 # 任务2的输出维度model = MultiTaskLearningModel()设置 MultiStatements 处理模式torch.set_num_threads(4) # 设置线程数为4torch.set_multiprocessing_sharing_strategy('file_system') # 设置共享策略为文件系统
您已经成功设置了 MultiStatements 处理模式,并创建了一个多任务学习模型,您可以使用该模型进行训练和预测,以同时学习多个相关任务。
下面是一个关于多任务学习中的MultiStatements处理模式的介绍示例,该介绍概述了不同处理模式的特点和用途:
 (图片来源网络,侵删)
(图片来源网络,侵删)
处理模式
序列处理
描述
按顺序处理每个Statement,完成一个再进行下一个。
用途
适用于Statement之间依赖性较强,需要顺序执行的场景。
优点
简单易实现;能够保证Statement间的执行顺序。
缺点
效率较低;无法并行处理。
并行处理
同时处理多个Statement,充分利用计算资源。
用途
适用于Statement之间相互独立,可以同时执行的场景。
优点
提高处理速度;充分利用计算资源。
缺点
需要考虑Statement间的同步问题;可能导致资源争抢。
管道处理
将多个Statement组成一个处理流程,前一个Statement的输出作为后一个的输入。
用途
适用于Statement之间存在数据依赖关系的场景。
优点
能够保证数据流在Statement间的正确传递;结构清晰。
缺点
需要精心设计Statement的顺序;可能导致性能瓶颈。
聚合处理
将多个Statement的结果进行聚合,生成最终结果。
用途
适用于需要对多个Statement的结果进行综合分析的场景。
优点
可以方便地对多个Statement的结果进行整合;灵活性高。
缺点
需要实现聚合逻辑;可能会增加处理复杂度。
联邦学习模式
在多个设备或节点上分布式地处理Statement,保护数据隐私。
用途
适用于需要对敏感数据进行多任务学习,同时保护数据隐私的场景。
优点
保护数据隐私;可以利用分布式计算资源。
缺点
需要解决通信和同步问题;可能会增加计算延迟。
分层处理
将Statement按照优先级或依赖关系分层,逐层处理。
用途
适用于Statement之间存在明显的优先级或依赖关系的场景。
优点
结构清晰;易于管理优先级和依赖关系。
缺点
需要设计复杂的分层策略;可能会导致处理流程繁琐。
 (图片来源网络,侵删)
(图片来源网络,侵删)
这个介绍提供了MultiStatements处理模式的基本概述,实际应用中可以根据具体需求选择合适的处理模式。
```相关文章推荐
- "Docker隔离性:如何保障深度学习模型的稳定性?实用技巧
- "Caffe 源码揭秘:深入解析 Caffe 框架的优势和应用场景
- "如何利用PyTorch进行深度学习模型预测?提高准确性的技
- "如何利用caffe深度学习平台进行模型预测?掌握关键步骤
- 1. "如何使用CUDA和MapReduce提高计算效率?探索并行计
- Caffe vs Caffe2: 了解两种流行的深度学习框架的差异
- 什么是TensorRT?为什么TensorRT在深度学习中如此重要?
- 如何选择深度学习主机?5个关键因素帮助你预测深度学习
- 1. "如何利用Python AI编程实例轻松入门深度学习" 2.
- “AI智能深度学习:深度学习模型预测的技术与应用指南”
SEO优化最新文章
- PHP扫描网站所有URL:如何确保网站安全扫描的完整性?
- C语言如何使用ODBC连接MySQL数据库? | 通过C#语言实现数据库连接的具体实例
- 如何使用车载导航视频格式转换器?快速解决导航视频格式不兼容问题
- 为什么使用pull命令部署失败?如何解决这个问题?
- 电商设计主要做什么?探究电商平台的设计重点与提升策略
- 在微信中查看别人的朋友圈不会直接在对方的朋友圈记录中留下痕迹。但是,如果你给对方的朋友圈点赞、评论或者转发,对方在朋友圈中会收到通知,并且在对方的朋友圈消息提醒中会有相应记录。
- “如何架设云服务器? 一步步教你快速搭建云服务器架构”
- "什么是SQLPlus权限?如何分配和管理SQLPlus权限?"
- “为什么苹果8p微信不会爆炸?了解安全科技背后的原理”
- Linux Mint支持UEFI启动吗?完全指南和解决方案





)


)
)


